
Calculating SHA and MD5 Hashes
This example demonstrates how to calculate Message Digest hashes - such as MD5, SHA-1, SHA-256, etc. - for your data.
Example Files
Get the example files. You can run the example flows in your Tweakstreet workbench to see the solutions in action.
Calculating a hash for a single field
In the most basic case, we’re interested in a hash that is calculated from a single piece of data, such as a name or address field. This can be useful when anonymizing data sets.
In the example file we’re anonymizing the name field by calculating a SHA-1 hash for it.
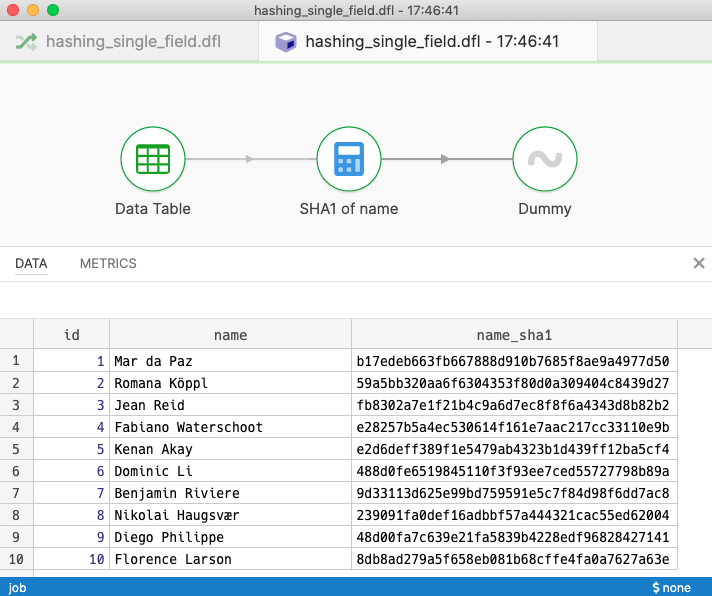 Basic flow calculating a SHA1 hash
Basic flow calculating a SHA1 hash
The calculator step is configured with the digest-hash function windget which defines a function that calculates digest hashes for us.
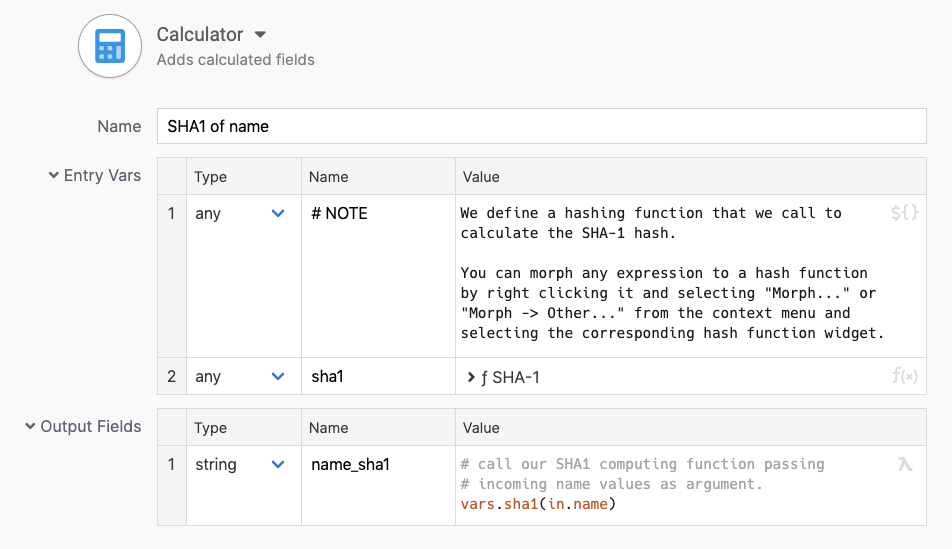 The calculator step calculates the SHA1 hash of the name field
The calculator step calculates the SHA1 hash of the name field
Calculating a hash for multiple fields
Say we’d like to hash many fields of a record. This is often useful when synchronizing data following an ‘insert-only’ strategy. Say there’s an index table containing hashes only, and we’d use it to quickly check whether a record is already present or not by looking for the record’s hash. We’ll use SHA-256 hashing for our example.
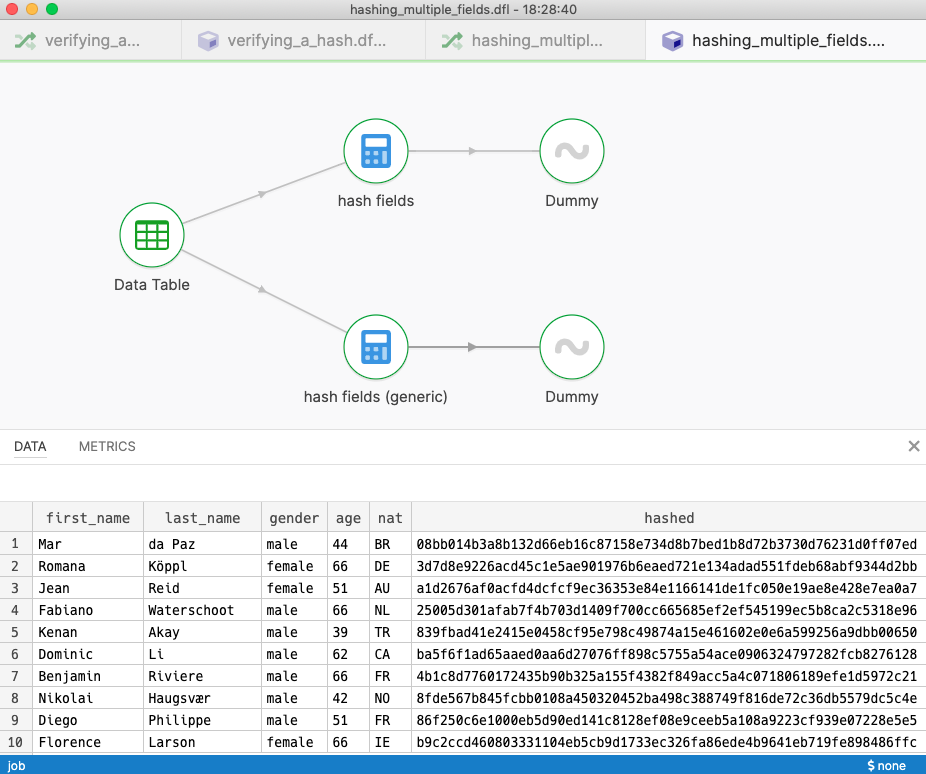 The example file demonstrates two ways to accomplish the same goal
The example file demonstrates two ways to accomplish the same goal
In the example file we’re calculating hashes for a subset of fields: first_name, last_name and gender. This strategy calculates hashes for each field first, puts them in sequence, and hashes the resulting sequence for the final result.
A field-by-field solution
We can implement the hashing field by field like so:
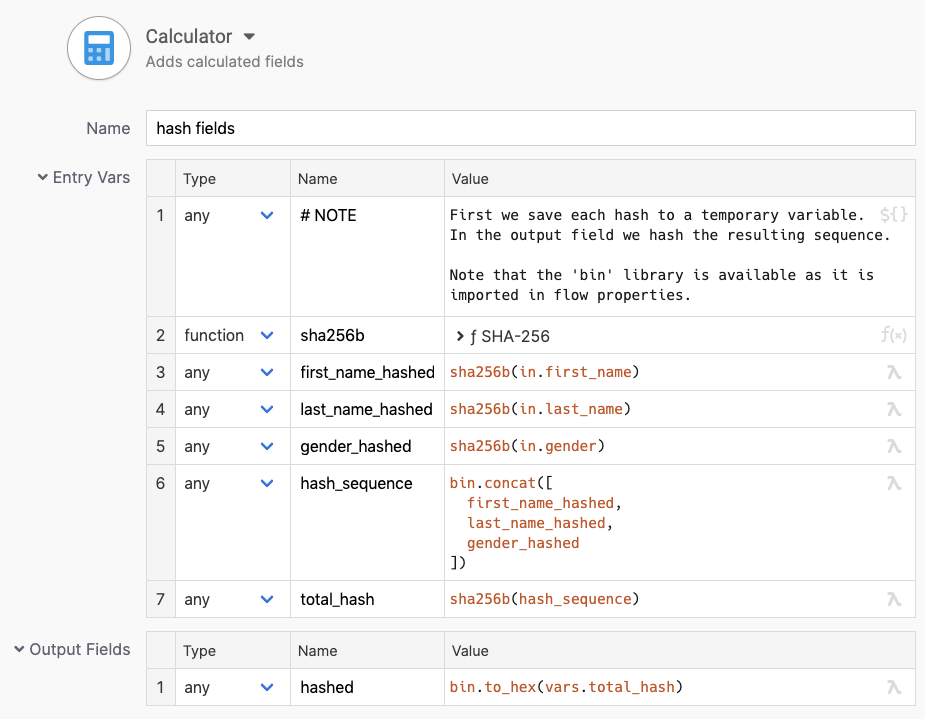 Step by step approach to calculating a compound hash
Step by step approach to calculating a compound hash
Note how the hashing function is configured to produce a binary result in this case. We’re keeping the individual field hashes in binary format, and we’re generating a text representation of the final hash only. This is a matter of convention. If another party needs to be able to replicate the hashing process, we need to be clear whether we hashed over the bytes of the intermediate hashes directly or over their hex string representation.
The step uses bin.concat to form a bigger binary value from the individual hashes, and hashes over that result again.
The resulting hash is converted to a hex string using bin.to_hex.
To use these functions from the standard library, the flow needs to import them in its flow properties screen.
A more generic solution
The example file has another branch which approaches the fields selected for hashing more generically. The calculator step defines a function that extracts the configured fields and generates the corresponding hash from a given row.
To do that it keeps a list of field names, maps over that list extracting and hashing the field values from any given row.
An approach like this makes the solution better suited to solutions where the field names to hash might come from a flow parameter, or even with the data itself.
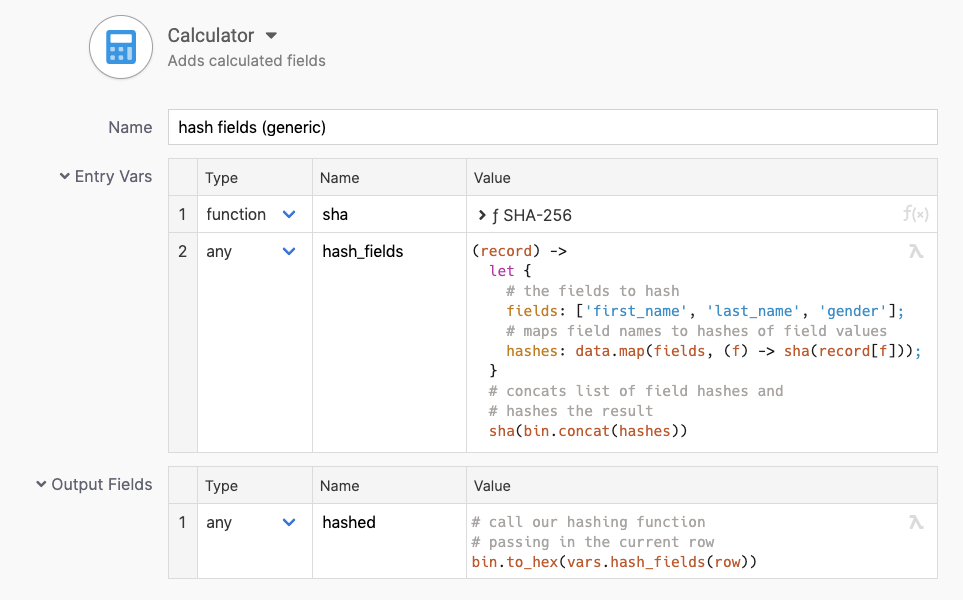 More generic approach to calculating a compound hash
More generic approach to calculating a compound hash
Verifying a given hash
Sometimes we’re given a hash, and we need to verify that it matches the data we got. We do this by re-computing the hash from the data and check for equality with the hash we’ve been given.
In the example file we’re given records as binary blocks, and each block comes with its own MD5 hash acting as a checksum. We need to verify that each block’s MD5 hash matches and filter out blocks that have problems.
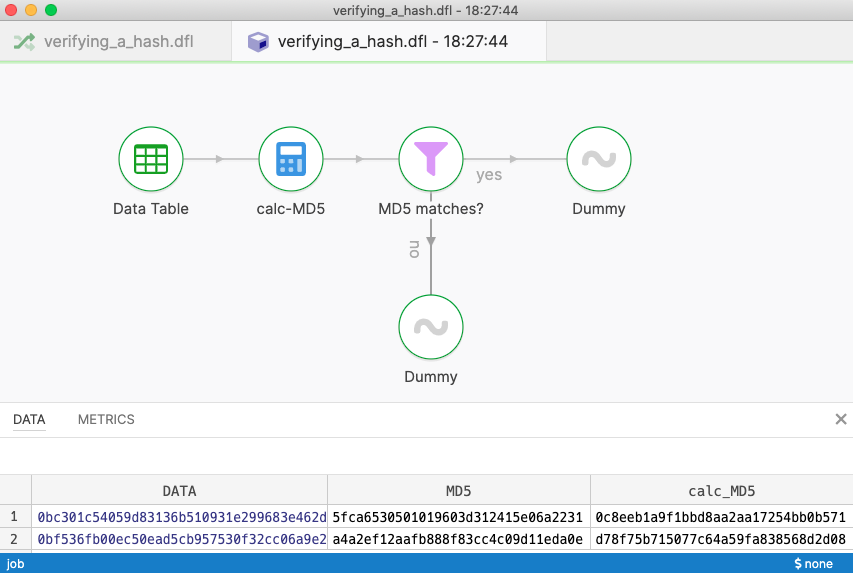 Flow verifying MD5 checksums
Flow verifying MD5 checksums
The calculator step computes the MD5 hash of the binary data blocks. We define our digest hash widget to provide us with an MD5 function this time.
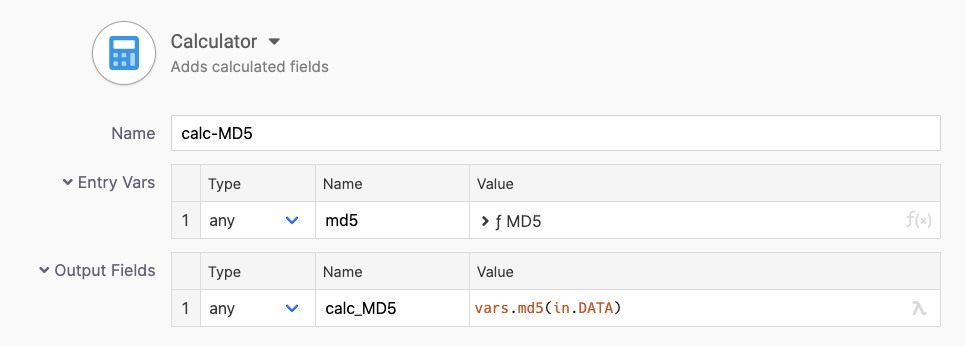 Calculator re-computing MD5 checksums
Calculator re-computing MD5 checksums
Once we have computed a MD5 checksum of our own we can check whether it equals the MD5 checksum given to us in the source.
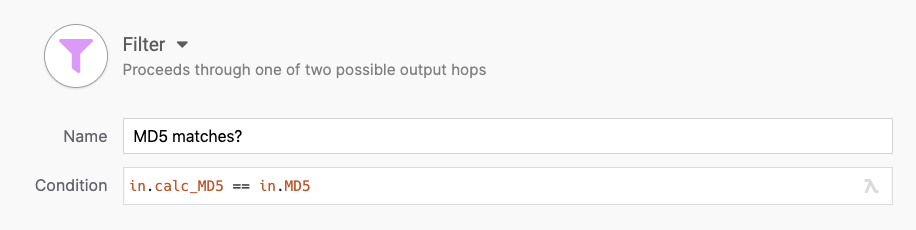 Filter step checks for equality of MD5 checksums
Filter step checks for equality of MD5 checksums