
Data Flows
Data flows perform tasks in parallel. A data flow begins executing all of its steps concurrently. Any rows that are generated by input steps, such as database query steps, or CSV reading steps, are passed on to connected steps down the line and processed as soon as they arrive.
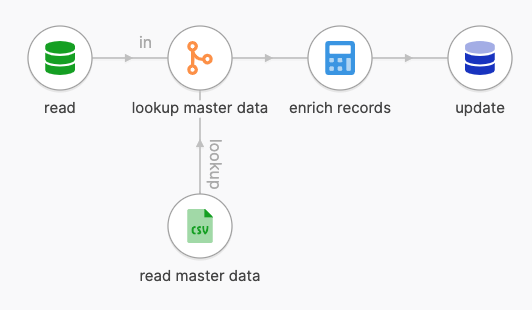
Above is a basic data flow structure. Records are read from a database, enriched with master data coming from a file, and written back to the database. All steps execute concurrently, and only a subset of all procesed records are in memory at any given time.
Configuration
Imports
Imports are bringing libraries and values from tweakflow modules into flow scope. The imported libraries are available in the entire flow, and can be used in all expressions.
- import standard libraries from
'std' - import tweastreet libraries from
'tweakstreet/<library name>' - import from your own modules using a path relative to the flow location such as
'./modules/my_module.tf'
An example import section might look like this:
# import the standard library
import core, data, strings, time, math, fun, locale, regex, bin, decimals from 'std';
# import additional json library
import json from 'tweakstreet/json';
Parameters
Parameters are named expression values that can be passed in when executing a flow. Parameter values are available in the entire flow. They are declared with default values which are used when the flow is invoked without specifying a value for a parameter.
Variables
Flow variables are named expression values that are available in the entire flow. They are typically used to specify flow-wide constants. They are also a good place to validate parameters, or calculate derived values from parameters.
Services
Services are named expression values that are available in the entire flow. They describe various kinds of resources or configuration such as database connections, server credentials, etc.
Specifying these items in the services section of the flow makes it easier to define them and reference them when configuring steps to use them.
Provided variables
Flows provide data about themselves in additional flow variables.
Execution model
Data flows start executing all their steps at once. There is no dedicated starting point. If a step has no predecessor step that feeds data into it, it is kickstarted with an empty row as input.
When a step executes, it performs its task, and potentially generates output rows passing them through its output gates to any connected steps. There are no semantic limitations on how many rows a step produces, or which output gates they are sent to.
A data flow finishes once all steps have finished processing rows.
Data rows
Data rows are dicts that are carried along the execution path. Steps processing them have the opportunity to read, add, remove and replace fields.
Execution success
A data flow finishes successfully when all steps finish processing without error.
Execution results
Data flows that finish successfully can provide a return value called the result. By default the result value is nil. The Set Flow Result step can set the result value explicitly. When running a flow through the Run Flow step, the flow result value is available as one of the step results.
A flow that fails does not provide a result value, it is always nil.
Multiple instances of steps
A data flow supports running more than one instance of a step.
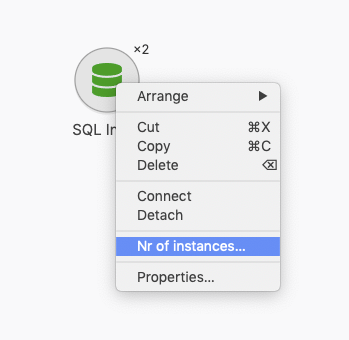
The expression governing the number of copies to launch can depend on flow parameters and variables. It is therefore possible to adjust the degree of parallelism using a parameter when launching a flow.
All instances of a step run indepdently. Under the hood each instance is created using the same configuration, and all instances are connected to the same previous and next steps - if any.
The following configurations are semantically identical:
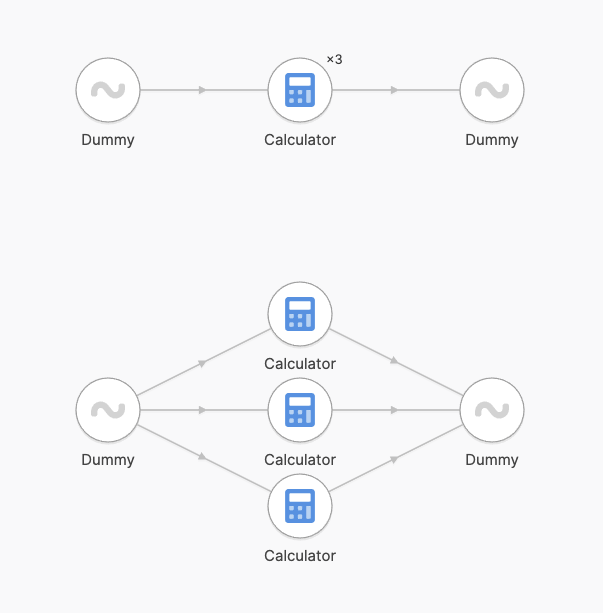
Why run multiple instances?
Each instance is executed by an independent thread. Substantial performance gains are possible in one of the following scenarios:
- The multi-instance step is CPU bound, and additional cores are available - running the python step or an external program for example.
- The multi-instance step is I/O bound, and dominated by I/O wait - such as when exchanging data with a DB-Server or HTTP server over a non-saturated network connection.
Configuring multiple instances of steps
Each instance of a step runs independently with its own copy of settings, vars, results etc.
Each instance carries information about how many total instances of the step are running and which index the current instance has.
instance.countis the number of instances of the step runninginstance.indexis the index of the current instance (0-based)
These values are useful to adjust the settings of an instance to be instance-specific.
It is often desirable to have an instance of an I/O reading step read only a subset of total data. An example is having a SQL input instance only read a portion of a table following a modulo selection pattern like this:
SELECT a,b,c FROM my_table WHERE id % ${instance.count} = ${instance.index}
If we have 4 instances configured, each runs a different query:
- instance 0 runs
...WHERE id % 4 = 0 - instance 1 runs
...WHERE id % 4 = 1 - instance 2 runs
...WHERE id % 4 = 2 - instance 3 runs
...WHERE id % 4 = 3
In total the entire content of the table is covered, each instance covering a subset of table rows. Another common way of partitioning read data is by a db-calculated hash value of one or more fields, such that fields with specific characteristics are read by the same instance.
All settings can be parameterized: in a similar fashion the setting for the instance’s DB connection can be relpaced with a formula such that each instance could read from a different server from a set of mirror replicas.
Processing lanes
When connected steps run with the same number of instances, tweakstreet keeps data flowing in lanes. See the following sample flow and the internal execution graph below:
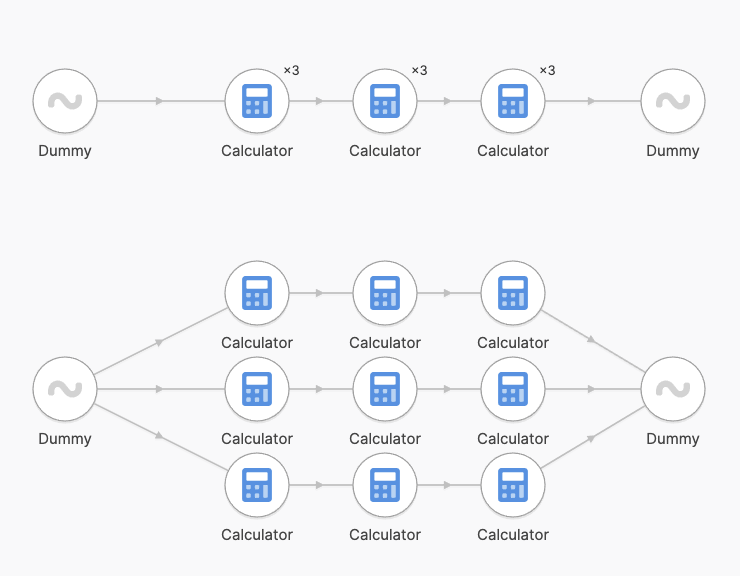
When connected steps run with a differing number of instances, tweakstreet re-distributes the data. There is some overhead associated with re-distributing processed rows, which is why it is desirable to plan most of a flow to follow fixed processing lanes.
As another example, below is a flow which results in entirely independent processing lanes:

In the above example each instance of the SQL Input step would use its instance.count and instance.index variables to read a different subset of total rows.
Partitioning
When tweakstreet re-distributes data because of a differing instance counts, you can influence which rows go to the same instance. Supply a partitioning function on a hop.
The partitioning function is invoked on every row passing through the hop. The entire row value is passed in as a dict.
Same return values of the function are guaranteed to go to the same target instance.
This makes it easy to ensure that certain rows stay together on subsequent lanes - for example if you return a field of the row, you can be sure that all rows containing the same value for that field will go to the same instance of the following step.
